
A Word Count Analysis of American Economic Association Programs (2011-2024)
The Rise of Gender, Race, and Inequality – and Data

Each year in January, thousands of economists descend on a US city for the annual Allied Social Science Association (ASSA) meetings. This convention consists of multiple conferences, the largest of which is run by the American Economic Association (AEA). The next meeting is coming up soon: January 5-7, 2024 in San Antonio, TX.
The AEA is the leading US association of economics researchers. With a focus on scholarship, the AEA directors and officers consist of professors at top research universities, elected by association members. The membership of the association is largely composed of university faculty, as well as other research active PhD economists at government agencies and private sector organizations.
The senior officers and directors of the AEA are responsible for the content of the meetings, although they delegate selection work to program committees whom they designate (see for example last year’s AEA program committee). The AEA allows for submissions of either individual papers, which the program committee organizes into sessions, or entire pre-packaged sessions consisting of several papers. In 2023, the individual paper acceptance rate was 9%, and the acceptance rate of complete session submissions was 30%.
As the research interests of the field of economics have changed over time, so have the focal topics of the AEA program. A simple analysis of the top 25 words in the AEA session names and paper titles of these conferences each year over the 2011-2024 period reveals some interesting facts.
The first figure below shows the top 25 words in the AEA session names and paper titles at the beginning and end of this period. Words that appear in the top 25 in 2011 but not in 2024 are shown in black with a circle in 2011; words that appear in the top 25 in 2024 but not in 2011 are shown in black with a diamond in 2024.

Around half of the words that occupy the top 25 in 2024 were not in the top 25 in 2011. The top-ranked words that made the top 25 list in 2024 but weren’t on the list in 2011 are:
· gender/gendered (#7)
· race/racial (tied for #8)
· data (#10)
· child (#12)
· inequality (#15)
Other words in the top 25 of 2024 that were not in the top 25 of 2011 are education, firm, inflation/inflationary, outcome, woman, dynamic, and disparity.
What are the words from the top 25 of 2011 that these newer words have replaced? These are crisis, trade, international, model, experiment, rate, school, choice, cost, analysis, program, and tax/taxation.
The overall picture confirms that the AEA is today significantly more interested in gender, race, and inequality than it used to be. At the same time, there has clearly been a rise in emphasis on data, and a resurgent interest in inflation.
There is some stability in words at the very top: the words evidence, economic/economics, market, and effect took 4 of the top 5 slots in both 2011 and 2024. While price/pricing and finance/financial have fallen, money/monetary, impact, and United States have risen.
Looking at only the bookend years of the sample period masks year-to-year movements. The next figure adds 2018 to the years shown on the graph. It presents much the same picture. Inequality and gender, as well as data, had already arrived in the top 25 in 2018 but have moved up in 2024. The relative decline of the AEA’s interest in prices seems to be a more recent phenomenon.

The next figures take a more granular year-by-year approach, presenting just the top 10 words but in each year from 2011 to 2024. The first shows the relatively stable five words that have appeared among the top 10 in every year between 2011 and 2024: evidence, economic/economics, market, effect, and policy.
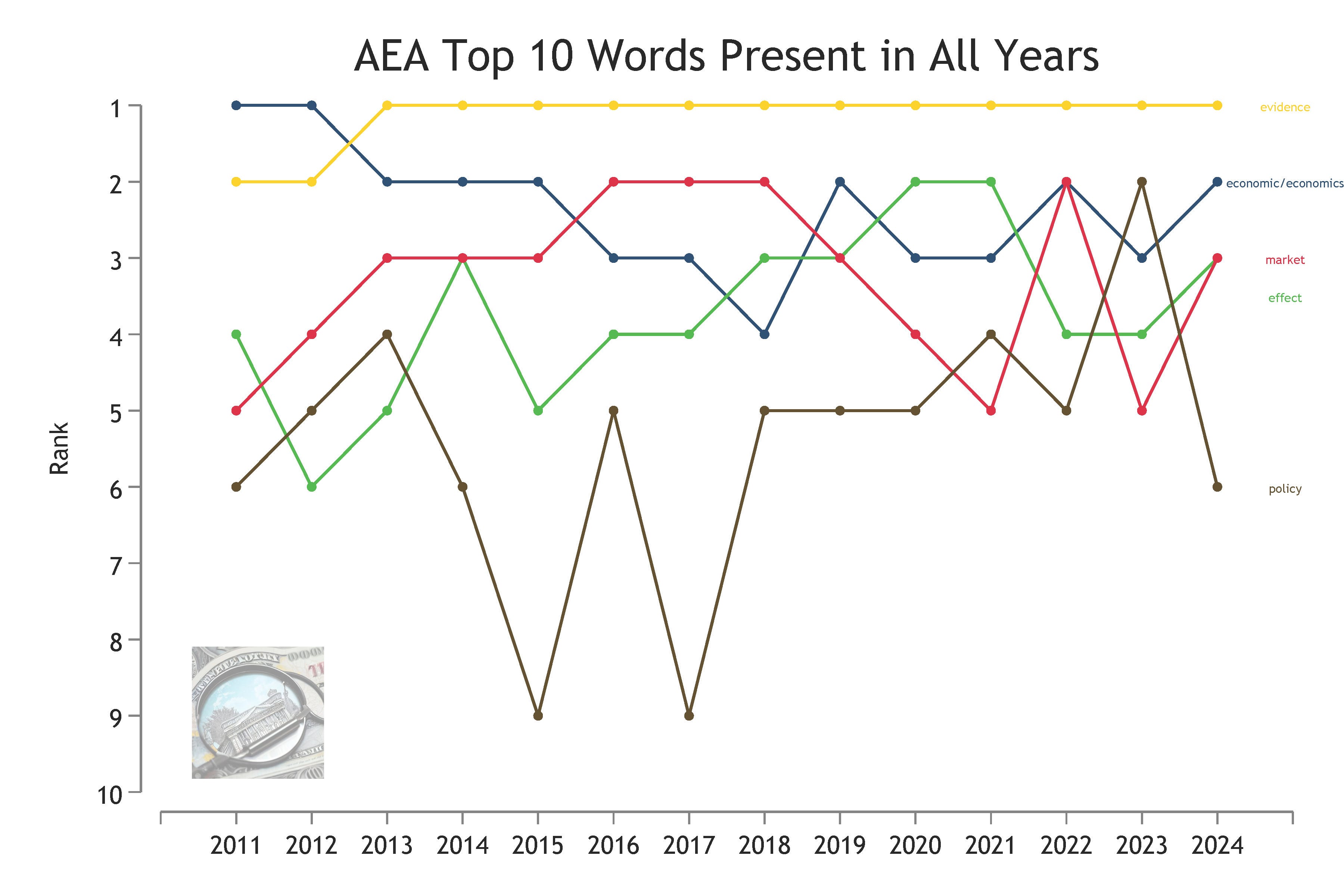
Finally, I present a graph the rest of the words in the top 10 in some year. This last figure shows that gender entered the top 10 in 2019, while race/racial and data entered the top 10 in 2023.

Capital had a couple good years in 2015-2016 when it held slots #8 and #9, but it was not in the top 10 (or top 25) either in 2011 or 2024. Tax/taxation also enjoyed a heyday in the middle of the last decade, even reaching #6 in 2016, but it is no longer among the top 10 or top 25 in 2024.
A remark about the field of economics attributed to Jacob Viner is, “Economics is what economists do.” The profession, as represented by the AEA, evidently isn’t as interested in capital or taxation as it once was, preferring the study of gender and race.
References to the United States in session and paper titles has bounced around somewhat. Whether its rise to a #5 position in 2024 primarily reflects the increased use of US administrative data or the fact that researchers working on race and gender disparity topics tend to be studying the US is a question for future research.
If you want more details on the methodology of how these figures were created, see below. Otherwise, I wish all who celebrate it a Merry Christmas, and everyone a Happy New Year. See you at the meetings!
Methodology
To conduct this analysis, we started by collecting data from the American Social Science Association’s (ASSA) annual meeting programs. We took the session names and paper titles for sessions affiliated with either the American Economic Association (AEA) or American Finance Association (AFA), from each year’s program from 2011 to 2024. Our analysis begins in 2011 as this was the first year the ASSA program website includes an html page that notes which association hosted each session, although in theory it is possible to go back further in time by scraping pdf versions of the program.
To scrape this data, we used a Python script which identified whether a session was hosted by either the AEA or AFA, and, if so, collected the name of the session and its respective papers, creating two raw data files, one for each association. If a session was jointly hosted by the AEA or AFA and additional organization, its associated data was included in the raw files. As the webpages for the programs differ in format over the years, three different scripts were used to scrape this data: one for the years 2011 to 2016, one for 2017 to 2020, and one for 2021 to 2024.
After collecting the raw data, the files were run through a script that removed duplicate session names and paper titles to ensure each one was only counted once. We then consolidated certain similar words together and accounted for some common two-word named entities. Noun-adjective pairs such as gender and gendered, inflation and inflationary, money and monetary, race and racial, and taxation and tax were mapped together. Similarly, the various forms of the word “United States” (such as US, U.S., USA) were all consolidated to one version as well. Common two-word cities, such as New York, San Francisco, and San Diego, were treated as one word. We then put all words in their lowercase form, and excluded common stop words (“and”, “but”, “is”, “a”, “do”, “I”, etc.) and non-alphanumeric entities.
To handle the more general inflected variants of words, we converted the tokenized entities to their base form using NLTK’s lemmatizer. NLTK is a platform providing interfaces for the building of Python programs to work with human language data. These word base forms (or “lemmas”) were then counted using the Python Collections module’s “counter”. The top 50 words for each year were then taken from this output.
I thank Aaron Gelberg for excellent research assistance.